This course provides an overview of the principles and applications of data science. The first part of the course deals with the acquisition and handling of data, with an emphasis on contextualizing data and framing data analysis. The second part of the course will focus on tools and techniques for data manipulation and visualization. The third part of the course will introduce students to several methods for modeling data. The course will present both theoretical frame-works and practical tools for implementing various algorithms for regression, classification, and clustering. Students will become proficient in Python based tools for data analysis including numpy, pandas, and scikit-learn.
Essential Questions
The organizing questions for the three sections of the course are:
- Getting and Cleaning Data
- Where does data come from and how do we make it useful?
- What is data?
- How do the tools we use obscure the data or help us understand the data more deeply?
- What are the human choices involved with analyzing and presenting data?
- Visualizing Data and Communicating Findings
- What are the human choices involved with analyzing and presenting data?
- How can data analysis and visualization inform policy? How can it mislead?
- How can we communicate effectively about data (with different audiences)?
- How do the tools we use obscure the data or help us understand the data more deeply?
- Modeling Data
- How do we validate modeling choices? Once I build a model, how do I know whether it’s good or not?
- Why do we model data? What can models help us to achieve or learn?
- What kinds of assumptions do we make when we build a model? How can models mislead?
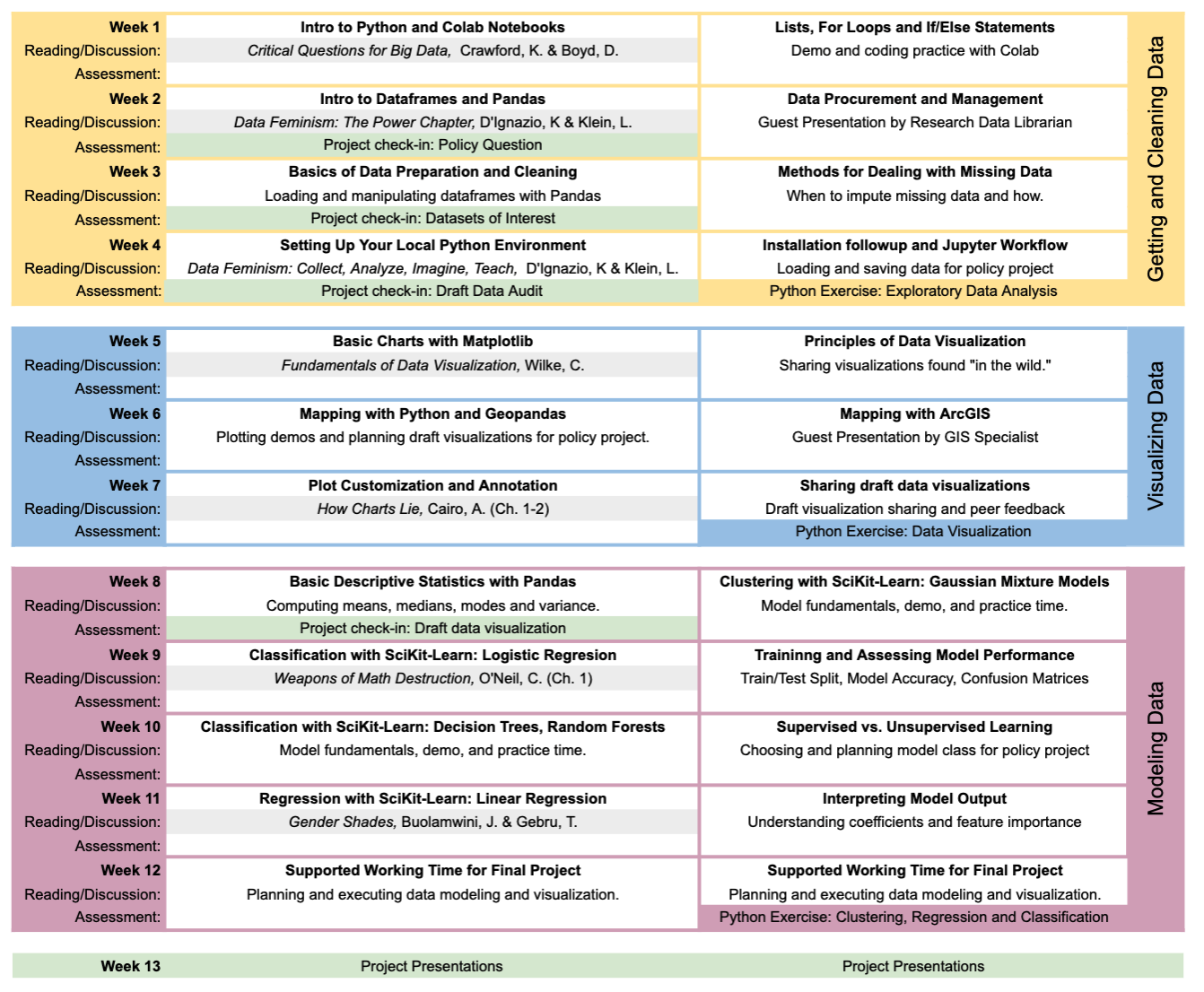
Semester schedule
Materials
Instructions for getting set up with Python, Jupyter and conda on your own computer
Colab notebooks for in-class demos and exercises
- Introduction to Python Basics
- Introduction to Dataframes
- Data Preparation with Python and Sample Solutions
- Classic Charts with Matplotlib and Sample Solutions
- Maps with Python
- Radial Charts with Python
- Introduction to Modeling with Python
- Introduction to Classification
- Classification and Regression with K Nearest Neighbors
Colab notebooks for Python exercises
- Exercise: Exploratory Data Analysis in Python
- Exercise: Data Visualization in Python
- Exercise: Clustering, Regression, and Classification with Python
Readings and journal prompts
Project
- Project Check-in: Policy Question
- Project Check-in: Identifying Datasets of Interest
- Project Check-in: Data Audit
- Project Check-in: Draft Data Visualization
- Final Submission Assigment and Rubric
License

These materials for Data Science for Global Applications by Karin Knudson and Anna Haensch are licensed under a Creative Commons Attribution-NonCommercial 4.0 International License.